n
Es importante señalar que System Platform puede ejecutarse también en un MONOPUESTO. No es necesario desplegar una arquitectura distribuida de aplicación. Dependiendo del tamaño de la aplicación, se verá la conveniencia de ejecutarlo de manera más o menos distribuida.
El no estar ligado a una Arquitectura fija, ya que los objetos pueden distribuirse sobre cualquier PC, hace que el proyecto asuma la característica de alta disponibilidad. Es decir, se puede desarrollar una nueva funcionalidad de la aplicación y luego ponerla en marcha, sin que el sistema deje de funcionar. Solo se tendrán que ejecutar los nuevos objetos desarrollados.
n
Esta independencia hace que en caso de que un determinado servidor pudiera estar saturado, lo único que se debe hacer es, desde la herramienta de desarrollo, hacer que una serie de objetos se ejecuten en otro servidor. Desde el punto de vista de visualización, control y recolección de históricos, este proceso de distribución de cargas es transparente.
n
El mercado está demandando la capacidad de Desarrollar Salas de Control de entornos distribuidos de forma sencilla. Esta sala de control debe tener la capacidad de permitir que la aplicación sea desarrollada tecnológicamente desde un único sitio (en este caso llamamos aplicación a desarrollo de Software, Instalación de Drivers de forma remota, Mantenimiento de Hardware…) y además permita a un usuario visualizar y controlar de una forma operativa, toda esa aplicación desarrollada.
n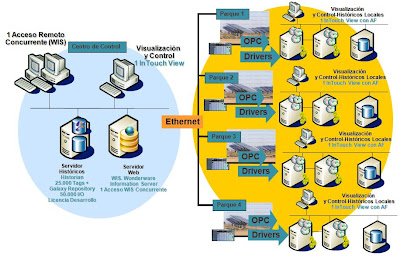
Del mismo modo, este desarrollo remoto, no debe estar condicionado a potentes comunicaciones. Se debe tener la capacidad de realizar este desarrollo y este mantenimiento con redes de banda baja (a nivel MODEM). La creación de centros de control con System Platform se realiza de forma eficiente gracias a las características de su tecnología:
Es importante señalar que System Platform puede ejecutarse también en un MONOPUESTO. No es necesario desplegar una arquitectura distribuida de aplicación. Dependiendo del tamaño de la aplicación, se verá la conveniencia de ejecutarlo de manera más o menos distribuida.
El no estar ligado a una Arquitectura fija, ya que los objetos pueden distribuirse sobre cualquier PC, hace que el proyecto asuma la característica de alta disponibilidad. Es decir, se puede desarrollar una nueva funcionalidad de la aplicación y luego ponerla en marcha, sin que el sistema deje de funcionar. Solo se tendrán que ejecutar los nuevos objetos desarrollados.
n
Esta independencia hace que en caso de que un determinado servidor pudiera estar saturado, lo único que se debe hacer es, desde la herramienta de desarrollo, hacer que una serie de objetos se ejecuten en otro servidor. Desde el punto de vista de visualización, control y recolección de históricos, este proceso de distribución de cargas es transparente.
n
El mercado está demandando la capacidad de Desarrollar Salas de Control de entornos distribuidos de forma sencilla. Esta sala de control debe tener la capacidad de permitir que la aplicación sea desarrollada tecnológicamente desde un único sitio (en este caso llamamos aplicación a desarrollo de Software, Instalación de Drivers de forma remota, Mantenimiento de Hardware…) y además permita a un usuario visualizar y controlar de una forma operativa, toda esa aplicación desarrollada.
n

Del mismo modo, este desarrollo remoto, no debe estar condicionado a potentes comunicaciones. Se debe tener la capacidad de realizar este desarrollo y este mantenimiento con redes de banda baja (a nivel MODEM). La creación de centros de control con System Platform se realiza de forma eficiente gracias a las características de su tecnología:
- Posibilidad de contar con una licencia corporativa que sea desplegada entre diferentes plantas o infraestructuras (desde 250 señales hasta 1.000.000). System Platform permite la posibilidad de utilizar la solución System Platform Single Node para utilizar una sola máquina para el despliegue de objetos.
- Crear un centro de control de forma modular. Por ejemplo, comenzando con la consolidación de datos de proceso o instalaciones en un repositorio único, para luego hacer una visualización y control conjunta vía sinópticos, para terminar con la introducción de funcionalidades MES, gestión eficiente de recursos energéticos o integración con herramientas de mantenimiento.
- Capacidad para tomar datos de diferentes SCADA´s y dispositivos de campo (vía OPC, mediante drivers, conversores, gateways, etc).
- Administrar de forma centralizada, tanto a nivel usuario final, como a nivel desarrollo toda la aplicación.
- Utilizar la tecnología Terminal Services para acceder de forma remota a las instalaciones de forma concurrente.
- Una problemática habitual consiste en la necesidad de tener datos históricos locales para luego agrupar estos datos en un histórico central. Es decir, distribuir varios Históricos en plantas locales para que estos datos se consoliden en uno central de forma automática. La plataforma incluye la opción de Tier Historian que facilita la integración de Historian distribuidos en un Historian Central.